微处理器 体系 结构
随着 高性能 计算的需求,计算机体系结构发生了很大变化。作为计算机核心部件的微处理器,其性能和复杂性(晶体管数、时钟频率和峰值)也按照摩尔定律增长。微处理器性能的改善在很大程度上归功于体系结构的 发展 和VLSI工艺的改进。体系结构的发展主要体现在三个方面,即超流水、多指令发射和多指令操作。
超流水技术主要开发时间并行性。流水线技术是RISC处理器区别于CISC处理器的重要特征。采用超流水技术,尽管可以减少关键路径中每级流水的时间,但同时也引入了更多的寄存器,进而增加了面积开销以及时钟歪斜问题。另一方面,深度流水在指令相关和指令跳转时会大大降低流水线的性能。
多指令发射和多指令操作均是开发空间并行性。多指令发射面临的首要问题是如何保持应用程序语义的正确性,MIMD、超标量和数据流技术是多指
令发射的典型结构。MIMD是并行计算的重要研究领域。超标量采用时序指令流发射技术,兼容性好,硬件开销大,功耗开销大,是目前多数商用高端处理器采用的主流技术。数据流采用token环技术,理论上可以开发出高度指令并行性。然而,其商用开发不成功,原因是运行时间开销大,尤其是token环匹配需要很高的时间代价。
多指令操作是当前体系结构的重要研究方向。多指令操作包括数据并行性开发和操作并行性开发。尽管在CISC处理器中均采用过这两种技术,但CISC给体系结构开发带来三个负面影响:一是CISC指令不适合流水处理,二是指令差异很大造成译码困难,三是编译器很难开发出有效的指令操作。与CISC处理器相反,多指令操作非常适合RISC处理器,其中SIMD和VLIW就是数据并行性和操作并行性的典型结构。
向量处理器和SIMD处理器都是利用多个操作数来实现数据并行性。但二者有很大不同。向量处理器对线性向量元素顺序操作,SIMD则对向量元素进行并发操作。对前者,每条指令只能作用于一个功能部件,执行时间较长;而后者在执行指令时可以作用于多个功能部件。向量处理器采用交叉存储器实现向量的访存操作,同时可对短向量进行有效操作,即对稀疏向量进行压缩以获得高性能。SIMD适合多媒体中的分组数据流,通过特定算法将长的数据流截成定长短向量序列,从而可以和向量处理器那样实现对定长短向量序列的高效处理。
VLIW是实现操作并行性开发的重要途径。CISC处理器采用垂直编码技术,而VLIW则采用水平编码技术,指令中的每个操作域可以并发执行。同CISC处理器相比,VLIW具有的优点是:指令操作域定长,译码简单;适合流水处理,减少CPI;编译器需要开发程序潜在的指令级操作并行性。传统VLIW的不足是指令带宽较高,二进制目标代码不兼容。VLIW和SIMD结构都能接受单一指令流,每条指令可以包含多个操作。但前者允许每条指令包含多个不同类型的操作,同时可以开发细粒度并行性。VLIW指令字较长,而SIMD具有很强的数据压缩能力。事实上,VLIW和SIMD技术相结合可以获得更高的性能加速比,且非常适合多媒体数据处理。
从微处理器体系结构和编译器界面划分的角度上讲,指令级体系结构可以分为顺序结构、相关结构和独立结构三类。在顺序结构中,程序不包含任何指令并行信息,完全通过硬件进行调度,即硬件负责操作间的相关分析、独立操作分析和操作调度,编译器只负责程序代码的重组,程序中不附加任何信息。超标量是该类结构的典型代表。在相关结构中,程序显式指定操作的相关信息,即编译器负责操作间的相关分析,而硬件负责独立操作分析和调度,如数据流处理器。独立结构完全由程序提供各个独立操作间的信息,即编译器负责操作间相关性分析、独立操作间分析和指令调度,VLIW是其主要代表。
超标量处理器架构
现代超标量处理器体系结构均基于IBM360/91采用的Tomasulo和CDC6600采用的Scoreboard动态调度技术,MIPS R10000和DEC21264微处理器均基于该体系结构。典型超标量处理器通常采用如下逻辑结构实现动态调度:寄存器重命名逻辑、窗口唤醒逻辑、窗口选择逻辑和数据旁路逻辑。Intel的Pentium处理器、Motorola的PowerPC 604和SPARC64则采用基于预约站的超标量体系结构。
www.55dianzi.com
两种 体系 结构的主要区别是:在典型超标量结构中,无论是推测还是非推测寄存器值都放在物理寄存器堆中;在预约站超标量结构中,推测数据放在重排序缓冲器中,非推测数据和已经执行完成提交的数据则放在寄存器文件中。在典型结构中,操作数不广播到窗口,而只将操作数标志TAG进行广播,操作数则送到物理寄存器文件。在预约站结构中,指令执行结果广播到预约站,指令发射时从预约站去取操作数。
超标量处理器性能与IPC(Instructions Per Cycle)和时钟频率的乘积成正比。时钟速率同系统结构的关键路径时延有关,而IPC和如下因素有关:程序中潜在的指令级并行性、体系结构字长宽度、指令窗口大小和并行性开发策略。超标量处理器一般通过增加发射逻辑提高IPC,这将导致
更宽的发射窗口和更复杂的发射策略。
众所周知,超标量处理器是通用 微处理器 的主流体系结构,几乎所有商用通用微处理器都采用超标量体系结构。而在DSP方面,LSI 逻辑公司的 ZSP200、 ZSP400、ZSP500和ZSP600均采用超标量体系结构。ZSP200采用并行MAC和ALU运算部件,2发射超标量结构;ZSP400采用双 MAC单元、4 发射超标量处理器体系结构;ZSP500为4发射体系结构、采用增强型双MAC和双ALU运算单元;ZSP600采用4MAC和双ALU运算部件,每个时钟周期发射6条指令。图1为ZSP400结构框图。
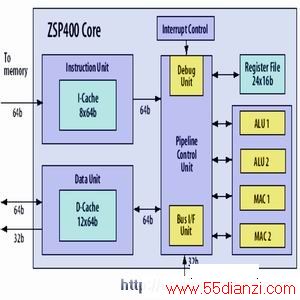
图1 ZSP400 内核超标量体系结构框图
ADI公司的TigerSHARC系列采用静态超标量体系结构。该系列采用了许多传统超标量处理器的特征,如load/store结构、分之预测和互锁寄存器堆等技术。每个时钟周期发射4条指令。而静态超标量的含义是指指令级并行性识别是在运行之前,即编写程序时确定的(事实上以VLIW结构为基础)。同时,Tiger SHARC系统处理器采用SIMD技术,用户可以对数据进行广播和合并。所有寄存器均是互锁的,支持简单的编程模型,该模型不依赖于不同型号间的时延变化。分支目标缓冲器BTB为128位,可以有效减小循环操作和其它非顺序代码的执行时间。图2为TigerSHARC系列中的ADSP-TS201S结构框图。
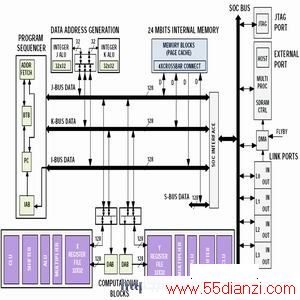
图2 ADSP-TS201S静态超标量体系结构框图
www.55dianzi.com
超长指令字VLIW 体系 结构
自从耶鲁大学的J.A Fisher于1979年首次提出VLIW体系结构以来,先后由耶鲁大学开发出基于跟踪调度(Trace Scheduling)技术的MultiFlow处理器和Cydrome公司Bob Rau等人开发的基于巨块调度(SuperbLOCk Scheduling)的Cydra-5处理器。但直到九十年代中期,基于VLIW结构的处理器基本上停留在实验室原型机阶段。因为VLIW本身固有的几个关键问题一直没有彻底解决,导致了其后的商用处理器体系结构从RISC转向了超标量和超流水,而不是VLIW。尽管如此,由于VLIW结构的许多优点仍然使许多研究机构竞相对该技术进行坚持不懈地研究,并在体系结构和编译器方面实现了突破,其中最重要的是解决了目标代码兼容问题并支持推断推测机制(尽管大部分处理器仅支持部分推断推测机制)。这之后出现了Philip的Trimedia、Equator的MAP1000A媒体处理器、ChromatIC的Mact、TI的TMS320C6XX、Transmeta的Crusoe以及INTEL和HP联盟提出的IA-64体系结构(EPIC)。事实上VLIW作为下一代 高性能 处理器体系结构的首选技术已成共识,该体系结构和优化编译器形成的SIMD指令流将更加适合多媒体数据处理。
本文关键字:微处理器 DSP/FPGA技术,单片机-工控设备 - DSP/FPGA技术






