德州仪器 (TI) 全新 TMS320C66x 数字信号处理器 (DSP) 内核不仅为屡获殊荣的 C64x+™ 指令集架构 (ISA) 带来了显著的性能提升,同时还在同一处理内核中高度集成了针对浮点运算的支持。浮点处理技术首次能够用于传统上仅能满足定点处理运行速度要求的处理器中。该 C66x DSP 的 ISA 同时支持单精度和双精度浮点操作,并全面兼容 IEEE 754 标准。这一完美组合造就了无与伦比的DSP,能够在完全无损定点或浮点功能的情况下将浮点优势引入高速嵌入式架构中。与其它很多可提供浮点协作单元的嵌入式处理器不同,TI 最新 C66x DSP 内核直接将浮点指令集嵌入到C64x 定点指令集中。在C66x CPU上,用户可以选择逐条执行浮点、定点指令,因为在 C66x 中浮点与定点运算能力已经被完全集成在一起。正是由于这样,到底使用定点 DSP 还是浮点 DSP 已不再是设计上的挑战,因为 C66x DSP 做到了双全其美。
在同一 DSP 内核中集成定点与浮点功能将使嵌入式系统算法的开发与部署方式发生根本性变革。这听起来似乎有点夸大其辞,不过事实的确如此。在定点数字系统中实施算法所付51系列串口通讯例程出的艰辛是不可估量的。但充分满足对速度的需求又使这一工作势在必行,因为到目前为止市面上还没有任何可供使用的快速浮点DSP。我们能够轻松、便捷地将采用 Matlab 等浮点运算工具开发的算法移植到 DSP 中,而无需费力转换为定点方式处理。借助 TI 新型 C66x DSP 的浮点计算能力,大多数转换工作已显得没有任何必要。
对二进制数字表示的回顾
包含 TI DSP 等在内的所有数字处理器均采用带比特串(0 和 1 组成)的二进制形式表示数字。数字表示精度取决于所使用的比特位数和表示格式两个方面。
定点系统使用比特表示一个固定取值范围,这些值既可以是整数,也可以是具有固定数量的整数及小数位的数字。动态取值范围因而显得十分有限,而且超出设定范围的值必须达到端点。
定点处理器通常采用每秒乘法计算次数表示其 16 位运算性能。为了充分利用处理器的处理能力(例如,为获得其宣称的全部性能),为这些处理器开发的算法不得不在一系列预先确定范围的数字上进行操作。在定点实施过程中无法高效执行难以预知范围或变化幅度大的数据集。
浮点表示通过采用科学计数法来提供更广的动态范围,从而可使用尾数(或叫有效数字)及指数进行表示。C66x 内核可对 32 个比特位表示的数值实施单精度浮点运算,其采用的表示形式如下:(−1)5 × M × 2(N−127),其中 S 表示符号位,M 表示尾数或有效数字位,而 N 则表示指数。S 只有一个比特位,N 有 8 个比特位,而 M 以 23 个比特位表示。 这样,数字表示范围为 2−127 − 2128,并具有 24 比特精度的有效位。相比而言,16 比特位的定点算法仅能表示 216 个数值(从 0 到 65535),故其内在数字表示的可变范围要小很多。所以当数据集或工作在该数据集上的算法不可预知、动态变化幅度很大的情况下,浮点数字表示法更受青睐。另外很重要的一点是,有效数字始终以‘1’作为第一个数字,因此其数值始终保持 24 位精度。
图1所示的完全隔离电路可监控?48 V独立通道的电流,精度优于1%。负载电流流经位于电路外部的分流电阻。分流电阻值应适当选择,使得在最大负载电流时分流电压约为50 mV。
AD7171 的测量结果以数字码形式通过一个简单的2线SPI兼容型隔离串行接口提供。隔离由四通道隔离器 ADuM5402 提供。除了隔离输出数据以外,数字隔离器ADuM5402还为电路提供隔离+3.3 V电源。
这一器件组合实现了一款精确的高压负供电轨电流检测解决方案,具有器件数量少、低成本、低功耗的特点。测量精度主要取决于电阻容差和带隙基准电压源的精度,典型值优于1%。
图1. 用于负高压轨的低端电流监控器(未显示去耦和所有连接)电路描述该电路针对最大负载电流IMAX下50 mV的满量程分流电压而设计。因此,分流电阻值为 RSHUNT = (50 mV)/(IMAX)。
运算放大器级的“地”连接到共模源电压(?48 V)。运算放大器级的电压由“悬空”的5.6 V齐纳二极管提供,该二极管偏置到约2 mA的电流,这样便无需独立电源。在无修改的情况下,该电路的源电压范围为?60 V至?10 V。
U1A将分流电压放大49.7倍,其中G = 1 + R3/R2。零漂移放大器 ADA4051-2 的失调电压很低(最大值15 μV),对测量的误差贡献不大。50 mV的满量程分流电压从U1A产生2.485 V的满量程输出电压(参考共模源电压)。
U1B的反馈环路中有一个具有大VDS击穿电压(70 V)的N沟道MOSFET晶体管,它将U1A的输出电压施加于电阻R5两端,所产生的电流流经R6和R7。来自U1A的2.485 V满量程电压产生0.498 mA的满量程电流,它在电阻R7两端产生2.485 V的满量程电压。R7两端的电压施加于ADC的AIN?。当MOSFET短路时,电阻R6和肖特基二极管D2为AD7171提供输入保护。
注意,ADR381、AD7171和悬空齐纳二极管的电源电压由四通道隔离器ADuM5402的隔离电源输出(+3.3 VISO)提供。
TI 如何创造性地在同一内核中同时集成浮点与定点技术
最新 C66x DSP 内核 —— 图 1 显示的 C64x+ DSP 是 TI 最新 C66x DSP 的前代产品。该内核由两个对称的部分 (A & B) 组成,每部分具有四个功能单元。一个 .M 单元包含 4 个 16 位乘法器。
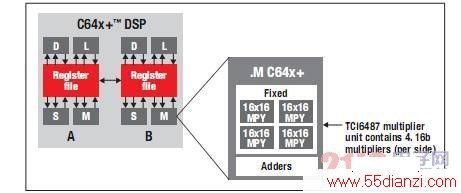
图 1 - TI C64x+ DSP
图 2 所示的 TI 最新 C66x 内核具有同 C64x+ 内核相同的基本 A & B 结构。请注意,.M 单元的 16 位乘法器已增至每个功能单元 16 个,从而实现内核原始计算能力提升 4 倍。C66x DSP 实现的突破性创新使得由 4 个乘法器组成的各群集可协同工作以实施单精度浮点乘法运算。
图 2 - TI 最新 C66x DSP 内核
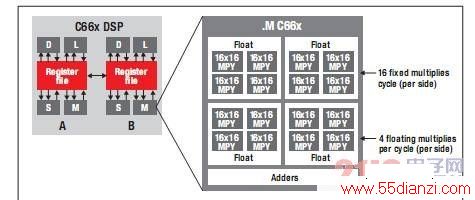
C66x DSP 内核可同时运行多达八项浮点乘法运算,加之高达 1.25 GHz 的时钟频率,使其当之无愧地成为市场上性能最高的浮点 DSP。将多个 C66x DSP 内核进行完美整合,即可创建出具有出众性能的多内核片上系统 (SoC) 设备。
浮点技术的成本 为使定点与浮点组件都能同时实现最佳性能,TI 专为该款最新的 C66x 内核开发了全新的浮点与定点指令,所有这些都对实现高效率的无线信号处理至关重要。由于采用浮点符号会带来额外的计算复杂度,从而导致了定点与浮点处理器“分庭抗礼”的局面。在定点运算情况下,加法、乘法等基本操作简单易行,但在浮点运算情况下,这些基本操作需要做更多工作量。比如两个浮点数相乘的情形:
请注意,指数需要相加操作,尾数则需要相乘操作。然后,最终 (M1×M2) 值需调整成 23 位的表示形式,这可能需要对指数的值也作更改。使用浮点技术进行所有基本运算时将需要很多额外的操作。
浮点计算带来的额外复杂度恰好说明了众多算法仅采用定点表示数和定点运算的原因。嵌入式处理器能够更快地运行定点运算,并且在众多情况下,只需要定点算法即可。例如,C66x DSP 内核在每个周期内都能执行 16 项定点乘法运算或者是 4 项浮点乘法运算。为使定点和浮点组件都能同时实现最佳性能,TI 为该款最新的 C66x DSP 内核开发了定点与浮点运算指令,所有这些都对实现高效率的无线基站信号处理至关重要。浮点指令 FPi 包括:
1. 单精度复数乘法
2. 矢量乘法
3. 单精度矢量加减法
4. 单精度浮点-整数之间的矢量变换
5. 支持双精度浮点算术运算(加、减、乘、除及与整数间的转换)并且完全为管线式
最新定点指令可实现最佳的矢量信号处理 (VSPi),其中包括:
1. 复数矢量和矩阵乘法,诸如针对矢量的 DCMPY,以及针对矩阵乘法的CMATMPYR1
2. 实矢量乘法
3. 增强型点积计算
4. 矢量加减法
5. 矢量位移
6. 矢量比较
7. 矢量打包与拆包
www.55dianzi.com
4
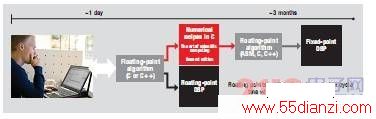
部分应用采用定点技术的隐性成本 尽管与浮点处理相比,DSP 能够实现更快的定点处理,但却不得不为特定算法在开发时间方面相付出代价。通信系统典型的设计流程是首先基于计算机模型开发相应算法,然后再将这些算法用在初始系统部署中。随着部署及应用范围的不断扩大,工程师便可将收集到的现实世界的数据带回实验室,以通过对算法的校正、调优提升系统性能。通常可使用 Matlab 或其他固有的浮点工具开发新的算法。接下来面临的挑战是如何在保持算法和系统性能的同时,将这些浮点算法转换为定点算法。复杂拙劣的算法会占用大量系统资源,从而导致系统的整体性能下降。在需要用到复杂处理的情况下,将 Matlab 中的代码移植到真实系统中就算耗费数周乃至数月的时间也不是什么罕见的现象。TI 最新架构具有原生浮点支持,从而使从浮点到定点的整个转换过程变得毫无必要。通过在 C66x DSP 上使用浮点指令,可轻松将代码从 Matlab 等工具中进行移植,并直接编译至 TI 的 DSP 中,如图 3 所示。
本文关键字:极限 DSP/FPGA技术,单片机-工控设备 - DSP/FPGA技术
上一篇:FPGA实现复接与分接系统






