在现代商业通用处理器上通常有用于计算系统总缓存失效率的部件,但是制定动态缓存分区策略需要更详细地知道各个线程的访存特征信息。一些特别用于获取线程访存行为特征的辅助硬件是必要的,本文将在1.3.1 节中给出相关介绍。
在取得必需的访存信息后,即可以根据不同的优化目标制定相应的缓存分区策略,在1.3.2 节和1.3.3 节中将分别从追求最大化吞吐量和公平性的角度对缓存分区进行研究。在1.3.4 节则针对缓存分区粒度过大(通常是按路分区)的问题介绍了一些解决方案。
1.3.1 访存监控器
大多数商业通用处理器都有一个硬件缓存监控器。缓存监控器包括两类计数器,一类用于计数系统总的访存数,另一类计数系统总的缓存失效数,由此可以计算出系统的缓存失效率。但如前所述,要制定动态缓存分区策略,还需要一些特别的辅助硬件来获取各个线程访存行为的特征信息。对于缓存分区而言,线程在各种可能的缓存空间下对应产生的缓存失效率是一个极其有用的信息。一种简单的做法是把每个线程在各种缓存配置下分别执行一次以获取相应缓存失效率。显然,这种方法过于低效,没有实用性。
当多个线程并行运行时,为了在不实际改变缓存配置的前提下,获取各线程在不同缓存空间对应的缓存失效率,Hsu 等人在文献[2-3]中提出一种访存监控器(memory monitor,MON)。对于N 路组相联缓存,每个MON 有N 个路计数器(way-counter)。
这组路计数器根据线程对缓存各路的使用情况按照LRU 次序排列。当对一个MRU(most recently used)缓存路中的缓存行发生缓存命中时,counter(0)增加1;当对一个LRU 缓存路中的缓存行发生缓存命中时,counter(N-1)增加1,以此类推。MON 另有一个计数器用于计数一个线程对共享缓存的总访存次数。
3 联合调度
前面两章分别对于共享缓存和DRAM 提出了相应的调度算法,但这只是系统中众多共享资源里最为重要的两种。实际上在多线程环境下,线程还会对于其他包括系列总线和I/O 设备等共享资源进行争夺,线程间互相干扰,对系统性能造成影响。
一方面,针对不同的共享资源独立提出的调度算法间从效果上可能互相矛盾。例如,同一个线程在共享缓存和主存处分别表现出的访存行为特征未必一致,再根据各自的调度策略,分别设定的优先级可能相反,使得调度失效。另一方面,从不同层面提出的调度策略之间也可能存在矛盾。例如,底层硬件层面的调度对线程的优化可能使得操作系统层面对于线程优先级的设定反转。因此,从全局出发,综合考虑所有共享资源,进行联合调度是极有研究价值的。
Ebrahimi 等在文献中为了解决线程的公平性问题,提出一个可以协调所有共享存储资源的机制称为公平性资源节源( fairness via sourcethrottling,FST),从而避免了需要为系统中每个共享存储资源提出单独的公平性机制。该机制使用前面在STFM中提到的线程减速比Mi=Tshd_i/Tsolo_i信息 , 用一组失效状态信息寄存器(miss statusholding/informatiON registers,MSHRs)记录各线程发向共享存储系统的请求,请求得到服务后相应寄存器清空,当没有可用的MSHRs 时,则禁止该线程向共享存储系统发送请求。系统的不公平性通过下式衡量:
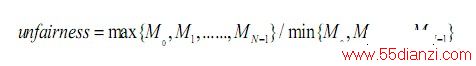
当unfairness 超过某个设定阈值时,表示有线程的性能降低程度已经严重影响到系统的公平性。可以通过调节可用MSHRs 数目来限制侵略性最强(或受影响最小)的线程向共享存储系统发送访存请求的速率,直到各线程的减速比基本保持一致水平,即unfairness 小于设定阈值,恢复受限制线程发送访存请求的能力。这个方法从源头上限制对共享存储资源的不公平性使用,从而无需从单个共享存储资源特别提出公平性的调度策略。
由于对DRAM 进行访存的速度提升远不及处理器速度的提升,访存DRAM 所带来的延迟常常是影响性能的一个关键因素。一个解决方案是,预测线程可能需要的数据,在处理器实际用到该数据之前就发送访存请求从DRAM 取回数据。该技术称之为预取(prefetching),已被证明确实能够有效改善系统性能,并被用于大多数商业处理器中。
然而,各个线程发向DRAM 的预取请求,同样存在对于系统资源的争夺和线程间的干扰,从而抵消由于预取部件所带来的性能改善。Ebrahimi 等人在文献中提出了分层预取侵略性控制( hierarchICal prefetcher aggressiveness control ,HPAC),类似于文献[24]中的FST,HPAC 通过从源头上限制预取请求的发送来改善系统的预取性能。
为了降低问题的复杂性,之前提出的调度策略都是针对没有采用预取技术的情况。为了更好地改善系统性能,我们总是希望调度策略和预取技术能够同时生效。然而,实验发现,即使采用已被证明有效的调度策略,在加入预取技术之后,调度策略仍然可能失效,使系统的性能受到影响。因此,Ebrahimi 等人在文献中的研究,解决了预取技术与调度策略的共存问题,并将文献中提出的FST 和HPAC 相结合。该项研究的基本思想包括如下几点:首先,预取请求涉及的通常只是处理器未来可能用到的数据,而非当前急需的数据,因此,除非某些预取请求有着和普通访存请求同样的重要性,预取请求的优先级应该低于普通的访存请求;其次,在所有访存请求中优先来自延迟敏感型线程的访存请求;并且,对预取请求按重要性分配不同的优先级;最后,FST 中对于处理器发送请求的调节可能与HPAC 对于预取请求的调节存在矛盾,通过协同考虑处理器和预取部件,可以有效降低对系统性能的影响。
Ebrahimi 等人在文献中的探索对于解决系统共享资源的联合调度是很好的启发。这些调度策略将所有共享资源抽象为一个整体,从源头上解决系统的公平性问题,但是并没有充分利用具体共享资源的访存特点。若能够将不同层次的调度策略有效结合起来,将会对对系统的性能有进一步的改善。
4. 研究展望
随着处理器核规模的增长,多线程对于有限的共享资源的争夺将愈发激烈,由此导致的对于系统性能的影响也将更加显着。为了缓解乃至解决这一问题,除了增加可用共享资源外,一个能够公平有效地在多线程间分配共享资源的调度算法也至关重要。学术界对此投入了大量的精力与时间。在各类共享资源中,对于系统性能有着最大影响的是共享缓存和DRAM 带宽。已有的研究也大多基于此,并已经取得了大量研究成果。
在第1 节中,我们分别以系统吞吐量和公平性为优化目标介绍了一系列对共享缓存的分区调度算法,并针对缓存分区粒度过大的问题给出了相关解决方案;在第2 节中,从利用线程的访存行为特征和借鉴网络路由算法等多个角度介绍了DRAM 的调度算法,并研究了基于机器学习的自我强化的调度算法;在随后的第3 节中,研究了从全局出发的联合调度算法,以解决针对不同共享资源的调度算法间相互矛盾的问题。上述研究都在一定程度上解决了我们如今所面临的问题,但是随着众核时代的来临,一些调度算法的复杂度和相应的硬件开销都可能大幅增长,导致这类调度算法失去实用性。针对调度算法在未来的系统中对共享资源的合理分配中所存在的应用潜力和面临的问题,我们认为仍然有问题可以展开进一步的研究:
1)如前所述,制定有效的缓存分区策略需要知道各线程的缓存需求,以及各线程从分配的单位粒度的缓存空间取得的收益。为了获取上述信息,Suh等人在文献中提出了的MON,随后,Qureshi等在此基础上提出了改进的UMON[4].基于UMON的系列研究分别针对共享缓存的吞吐量和公平性做出了有效改进。在文献中提出的zcache又解决了缓存分区粒度过大的问题,可以以较小的粒度将共享缓存分为数十个分区,使得缓存分区策略的可扩展性增强,能够应用于更大规模的CMP系统中。但是由于利用UMON 获取信息需要在每个核保留一份标签目录备份ATD.当核数较多且共享缓存较大时,会产生比很大的硬件开销。另外,如图1 所示,各个核将UMON 收集的信息送至一个缓存分区模块,集中进行缓存分区策略的制定。这种全局式的做法在众核时代会导致缓存分区模块面临过高的计算复杂度。
下一步研究,可以采用分布式的缓存分区策略:
由于共享数据的存在,先按照线程来源将共享缓存划分为几个子区,每个子区内的线程应该来自同一应用,共享某些数据;然后在各个子区内,根据不同线程的需求制定适当的缓存分区策略,每个子区还应该保留一部分缓存空间来存储共享数据。分布式的缓存分区策略一方面可以大大降低计算复杂度,同时又充分利用了缓存分区以及共享数据的优点,将会更好地提高系统性能。
另外,设计一类新的缓存替换算法,使其能够区分对待来自不用线程的不同请求,并执行适当的替换操作,也能够有效缓解共享缓存的争夺,并且避免了缓存分区所带来的开销。由于这种新的缓存替换算法需要更多的信息,可能需要在缓存的Tag中加入一些新的域,替换算法的复杂度也会增加。
2)对于DRAM 的调度策略,现有的研究方向可以主要分为两类。一类研究大多从组成访存请求的底层操作出发,充分利用DRAM 结构特点和线程的访存行为特征,例如行缓存相关性,块级并行性以及访存密集度等;这类研究能够有效利用DRAM带宽,有助于提高系统吞吐量。另一类研究则从网络公平调度算法得到启发,以DRAM 系统的公平性为优化目标,其中以FQM和STFM等为代表;这类研究存在的问题是将访存请求抽象为一个整体看待,没有充分利用DRAM 的结构特点和线程的访存行为,系统吞吐量往往不高。一个将这两类研究的优点有机结合起来的算法,能够同时做到改善系统公平性并保证吞吐量。






