图9. 借助队列结构,可以实现多个循环间的数据共享。
图9所表示的是典型的所谓生产者/消费者循环结构。在此例中,一个高速数字化仪在一个循环中持续采集数据,并在每次迭代中将新的数据集传递至FIFO队列。消费者循环仅需监视队列的状态,当每个数据集可用时将其写入磁盘。采用队列的意义在于这两个循环均可相互独立执行。在上例中,高速数字化仪可以持续采集数据,即使这些数据写入磁盘时存在一定的延迟。与此同时,其它的采样仅需存储在FIFO队列中。通常来说,生产者/消费者流水线方法,通过更有效的处理器利用率,提供更高的数据吞吐量。这一技术优势在多核处理器环境下更为显著,因为LabVIEW可以动态分配处理器线程至每个处理器核。
对于一项在线信号处理应用,您可以使用三个独立的while循环和两个队列结构,实现其间的数据传递。在此应用情况下,一个循环将从一台仪器采集数据,一个循环将专门执行信号处理,而第三个循环将数据写入到另一台仪器。
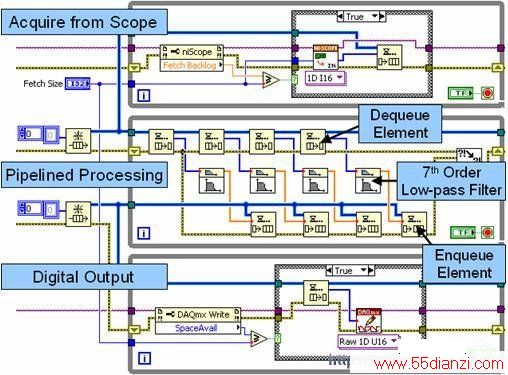
图10. 该模块框图描述了带有多个循环与队列结构的流水线式信号处理。
图10中,最上面的循环是一个生产者循环,它从一个高速数字化仪采集数据,并将其传递至第一个队列结构(FIFO)。中间的循环同时作为生产者和消费者工作。每次迭代中,它从队列结构中接收(消费)若干个数据集,并以流水线的方式独立对其进行处理。这种流水线方式通过支持高达四个数据集的独立处理,实现了在多核处理器环境下的性能改进。注意,中间的循环同时也作为一个生产者工作,将处理后的数据传递至第二个队列结构。最后,最下面的循环将处理后的数据写入至高速数字I/O模块。
并行处理算法改善了多核CPU的处理器利用率。事实上,总吞吐量取决于两个因素,处理器利用率和总线传输速度。通常,CPU和数据总线在处理大数据块时工作效率最高。而且,我们可以进一步使用具有更快传输速度的PXI Express仪器,减小数据传输时间。
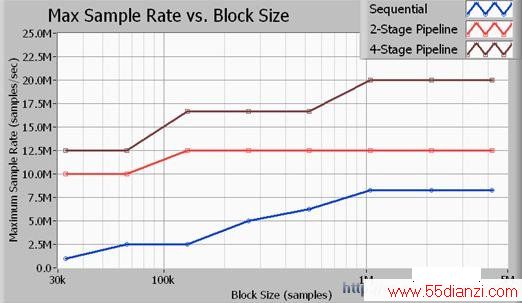
图11. 多循环结构提供比单循环结构高得多的吞吐量。
图11描述了最大吞吐量和采样率的关系,采样数据块大小以采样点数来计算。此处所描述的所有标定都是围绕16位采样进行的。此外,所采用的信号处理算法为一个截止频率为采样率的0.45倍的7阶巴特沃兹低通滤波器。如数据显示,您可以在4阶流水线式(多循环)方式下达到最大数据吞吐量。注意,2阶信号处理方式获得了比单循环方式(顺序)更好的性能,但其CPU的利用率低于4阶方式。上面所列的采样率均为NI PXIe-5122高速数字化仪和NI PXIe-6537高速数字I/O模块的输入和输出的最大采样率。注意,当采样率为20 MS/s时,应用总线的输入和输出的数据传输率均为40 MB/s,所以总的总线带宽为80 MB/s。
而且,应当考虑的是,流水线式处理方式在输入与输出之间确实引入了时延。所引入的时延取决于几个因素,包括数据块的大小和采样率。下面的表1和表2比较了单循环和4阶多循环架构中的实测时延随数据块大小和最大采样率的变化情况。
表1和2. 这两个表格描述了单循环和4阶流水线的时延。

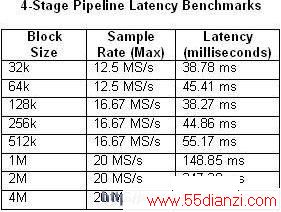
如您所推测,当CPU的使用率接近100%时时延也随之增加。这一点在采样率为20 MS/s的4阶流水线范例中尤为明显。相比之下,任何一个单循环范例的CPU使用率都几乎不会超过50%。
总结
基于PC的仪器系统,如PXI和PXI Express模块化仪器,从 多核处理器 技术的进步和数据总线速度的提高中获益匪浅。当新型CPU通过添加多个处理核改进性能时,并行或流水线式处理结构在最大化CPU效率时是必须的。幸运的是, LabVIEW 通过将需要处理的任务动态分配至每个处理核,解决了这一编程难题。如上所述,您可以通过将LabVIEW算法结构化以利用并行处理,实现性能的显著提高。
本文关键字:处理器 DSP/FPGA技术,单片机-工控设备 - DSP/FPGA技术






