内容摘要
随着泄漏功耗成为待机模式下的主要能耗,降低泄漏功耗也成为客户实现节能的主要途径之一。故现有的实现流程中需要采用快捷的解决方案,不仅对设计收敛影响最小,还应尽可能地缩短执行的汇聚时间。
建议的方案适合于那些采用双/三重 Vth (阈值电压) 技术、无需对现有 RTL 至 GDS 流程做任何修改的设计。
引言
泄漏功耗是固有的静态功耗,与开关及内部功耗 (定义为动态功耗) 共同构成总体功耗。
泄漏功耗与应用无关,主要是来自于:
● 源漏亚阈值 (sub-threshold) 电流,这是阈值电压降低以致沟道不完全关断的结果。
● 栅极到沟道的泄漏电流。
在多Vth技术中,亚阈值电流与Vth成指数关系,故低Vth单元的速度更快,但泄漏功耗也要大得多。
随着工艺尺度的缩小,这种情况愈加严重,而且在90nm及以下工艺节点,对大多数移动应用而言,这一问题越来越显著。
降低泄漏功耗是一项贯穿架构设计、VLSI设计、综合、P&R (布局布线) 直至Signoff (完成) 的任务。
功率设计包括减少关键和次关键路径的数量,以便在可能时让更多的单元被映像到高Vth上。
智能综合 (smart Synthesis) 与P&R的使用对设计的最终泄漏模式也有很大影响。
本文介绍的泄漏减少方法焦点在于流程实现的最后阶段,而且,虽然它主要是针对PrimeTime编写,却并不局限于某个专用P&R/Signoff工具。
方法描述
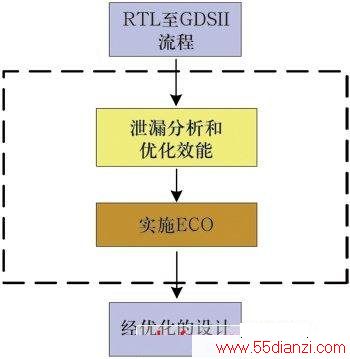
1.全流程概述
这种泄漏功耗优化方法瞄准最后阶段的后版图设计工作。其概念是让设计利用基于多个Vth的交换策略,提前一步实现最大泄漏的优化。
图1是整个流程的模块示意图,其中黄色和褐色矩形框代表泄漏优化。这个用于验证客户设计的系统运行在PrimeTime/StarExtract原始signoff环境下。
这种方法在完整的RTL至GDSII流程之后让最终设计进入原始signoff环境,然后开始搜索那些能够被交换到相应的更高Vth而又不会影响设计性能的单元。
基本上,这意味着这种优化将在设计的正Slack (时间裕量) 路径上进行。
在优化过程中,需检查下列设计参数:
● 建立时间违反
● 设计规则,如最大传输时间 (max_transition) 违反和最大电容 (max_caPACitance) 违反
● 由衰减受害者 (vICtims) 引起的串扰 (Crosstalk) 违反
● 时钟网络 (CLOCk nets) 设计规则
● 不应被接触或改变的特殊单元和结构
● 不同模式和边角 (比如功能性/测试模式WC/BC 等)
泄漏减少流程的第一个阶段 (即示意图中的黄色矩形框) 是优化流程中主要的耗时部分,并涉及利用PrimeTime“what-if”分析的搜索和交换策略。这一步骤会反复进行,直到找到所有适合交换的单元。
优化流程的第二阶段 (即示意图中的褐色矩形框) 是后版图设计 (ECO) 上的交换执行,RC提取 (RC-Extraction) 和整个STA 运行,并重新运行全部signoff 环境。
优化流程在这一阶段对“what-if”分析与全部RC提取之比较后发现的违反错误进行修正。与PrimeTime的快速计算以及总体运行时间减小的的优点相比,这些错误就相对不起眼了。因此,这一步骤的反复次数应该较小。该阶段的缺点是需要重新运行完整提取,从而增加总体运行时间。
在所有违反都得到修正 (第二阶段) 之后,优化设计的输出在功能性上与原始的设计版图相同,但大大减少了不必要的低/标准Vth单元,因此降低了功耗。
这种方法节省的总体功耗取决于RTL编码以及RTL-to-GDS实现流程早期阶段的泄漏意识。不过,利用这种流程可确保设计在Signoff要求方面得到最大限度的优化。这个问题十分重要,因为实际实现和Signoff优化之间总是存在差距,而在优化流程之后,这一差距可被减小。
2.交换算法
这种方法的目的是尽可能找出非时序关键路径 (即正Slack路径) 上的低/标准Vth单元,并用高Vth单元来替代,同时不影响时序或任何其它设计要求。
这种算法的主要概念是根据其所影响的端点数目对标准/低Vth单元进行分类。
比如,经过单元D、E 和 F终止于单个端点 (“端点1”和“端点4”) 的路径,由于它们只影响一个端点,故标注为#1 (或“group_1”)。
同样地,单元B和C属于#2 (或“group_2”),因为它们影响两个端点 (“端点2”和“端点3”),“group_2”……“group_n”以此类推。
对单元进行分类和标注之后,我们就可以从“group_1”开始,在一条正Slack路径上执行单元的递增式交换,然后是“group_2”…… “group_n”。在 PrimeTime中,利用“what-if analysis”来完成这一任务。
在任何两个邻近组“group_n”和“group_n+1”之间,算法都进行时序更新,以便在对“group_n+1”的任何单元进行交换之前,考虑到“group_n”上执行的交换。这是为了避免因虚假交换导致稍后必需修正 (重新交换)。
在进入“group_n+1”之前,对“group_n”中的所有可能单元都进行交换测试。这么做的目的是确保整个设计的最大交换次数。
举一个简单的例子来说明这种方法的原理:
路径1:A --> D --> “端点 1”,正Slack +50 ps
路径2: A -->B --> C -->“端点 2”,正Slack +70 ps
此外,假设在下列单元上交换到高Vth将导致:
● 单元D和B的单元延时将增加30 ps
● 单元C的单元延时将增加35 ps
● 单元A的单元延时将增加45 ps
现在,对这两条路径的泄漏优化,我们有两个选择:
● 选择1:把单元A交换到高Vth;这将在路径1上产生 +5 ps 的Slack,在路径2上产生 +25ps Slack。不过,这并非最佳方法,因为它不利于交换更多的单元 (B、D和C),节省的总体泄漏功耗较少。
● 选择2:把单元D交换到高Vth,这将在路径1上产生 +20 ps 的Slack;交换B和C将在路径2上产生 +5ps Slack。这种方法是迄今最好的方法,节省的泄漏功耗较大 (假设单元B、C和D的总体泄漏功耗大于单元A的泄漏功耗。)
此外,在交换某个单元时,我们必须把影响相同端点的所有其他组单元排除在外。如上例,若我们现在在“group_2”中,并交换单元C,则我们就必需在下一次搜索中把“端点2”和“端点3”除去,直到时序更新完成。只有这样,才能获得路径的正确时序,然后我们可以继续检查单元B的交换。否则,就可能导致虚假交换,而过多虚假交换也许会造成路径出现负Slack。
3.重新交换违反者 (violators)
由于PrimeTime“what-if”分析的结果可能不同于执行ECO及运行整个Signoff的结果,在完整提取之后常常少有违反出现,同时没有在Signoff 运行之前检测。这是因为单元交换会造成单元电容的变化。在执行“what if”时,PrimeTime必需对这种变化进行“在线”重新计算,同时在整个Signoff下重新提取,以提高精度。显然,PrimeTime的重新计算要快得多,并因此让整个方案具有可行性。
把产生违反的单元SwapPINg-back (换回) 到其原始形式的次数应该尽量小。
因此,Swapping-back的情况与2.2节描述的过程相反。
一般而言,每一个被交换过的单元都被标注为“已交换的”,故在执行重新交换时,我们需要从违反端点沿路径往回搜索,找到之前“已交换的”单元,就把它交换回原始形式。
为了有效完成这一工作,并尽量减少换回次数,我们首先换回那些影响端点数目最多的单元。
且看下面的简单例子:
假设A、B、C和D是准备交换的单元,但在执行ECO、提取 (即Signoff) 之后,在“端点1”、“端点2”和“端点3”上存在建立时序违反,出现较小的负Slack:
路径1: A --> D --> “端点1”,负 Slack -3 ps
路径2: A -->B --> C --> “端点2”,负 Slack -5 ps
本文关键字:如何 EDA/PLD技术,单片机-工控设备 - EDA/PLD技术






