
图5:两个处理器共享局部数据存储器
直接互连的数据端口
处理器直接相连可以减少通信开销和时间。这种连接方式将数据从一个处理器的寄存器传送到另一个处理器的寄存器和执行功能部件。直接互连的一个简单例子如图6所示。当第一个处理器向输出寄存器写一个数值(通常作为计算的一部分)时,该值将自动出现在处理器的输出端口上。同样的数值可以立即输入到第二个处理器进行相应的数据操作。
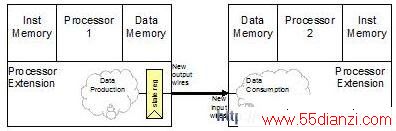
图 6:处理器到处理器之间通过端口直接进行访问
数据队列
任务之间通信的最高带宽机制是数据队列的硬件实现。一个数据队列可以使系统获得每个时钟周期传输一次的数据速率,或者在宽操作数位数的情况下可以达到每秒10GB的传输速率(每个操作数几十个字节,时钟速率几百兆赫MHz)。生产者和消费者之间的握手信号隐含在处理器之间的接口和数据队列的头信息和尾信息之中。
专用处理器允许数据队列作为指令集扩展的一部分直接进行硬件实现。数据队列可以通过一条专门指令来说明,队列可以作为结果值的目的或者使用输入队列值作为源。这种形式的队列接口方式如图7所示,该队列允许用户建立一个新的数据值,或者每个队列接口使用一个时钟周期。
www.55dianzi.com
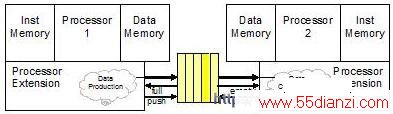
图 7: 硬件数据队列机制
数据队列对任务间的性能有一定的影响。如果数据队列生产者和消费者速率高度一致,那么队列长度可以比较短。如果队列生产者或者消费者速率不同,那么需要设计深度队列来弥补二者之间的失配。
由于处理器执行部件的队列接口对商用处理器核而言具有极其重要的特性,因此更加深入地对接口机制进行一些探讨是非常必要的。数据队列接口通过如下TIE语法格式添加到Xtensa LX处理器中:
queue
上面语法格式定义了数据队列的名称、宽度和队列的方向。一个Xtensa LX处理器可以包含300多个队列,每个队列宽度可以高达1024位。设计人员可以采用数据队列来对处理器性能进行折中,即在快速、窄带处理器接口和慢速、宽带接口之间进行折中以获得系统高带宽和高性能的目的。
图8为TIE队列和简单的Designware FIFO队列之间的连接,这种连接方式非常容易。TIE队列的push 和 pop操作由FIFO的队列空和队列满状态信号进行门控,这样可以使设计与Designware的 FIFO控制模式保持一致。
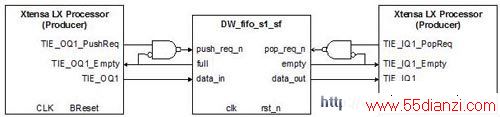
图8:采用TIE队列的Designware同步FIFO示意图
(diag_n输入驱动为高且almost_full、 half_full、almost_empty和 error输出均未用)
TIE队列可以和寄存器操作数、系统状态或者存储器接口那样直接为TIE指令提供输入和输出操作数。下面的TIE语法格式建立了一条新的指令,该指令对输入数据队列中的数据进行累加,然后送给寄存器文件。
operation QACC {inout AR ACC} {in IQ1} {
assign ACC = ACC + IQ1;
}
图9表示TIE队列是如何像其它指令操作数那样在Xtensa LX处理器中使用的。

图9:TIE队列作为指令操作数使用
Xtensa LX处理器本身包括一个两项的数据缓冲器,用于缓冲系统设计人员定义的每个TIE队列。每个队列的两项数据 缓冲器所占用的面积大大小于一个加载/存储处理单元。因此,TIE队列接口所占的处理器面积是完全受到设计人员所控制的,并且可以按照需要增大或者减小。
数据流直达处理
数据端口和数据队列与可配置处理器执行部件直接相连,这种互连允许处理器应用数据流直达技术进行处理,而那些应用在以前是为手工编写的RTL代码逻辑块预留的。将数据队列和输出队列接口与设计人员定义的执行部件相结合就可以建立一个在处理器内部由固件控制的处理模块,该模块可以从输入数据队列中读取数据,对这些数据执行计算,然后按照流水线方式每完成一个“输入-计算-输出”周期就将计算结果输出。图10表示一个简单的系统设计,该系统有两个256位的输入数据队列,一个256位的输出数据队列和一个256位的加法器/多路器执行部件。尽管该处理器扩展是在固件模式下进行控制的,但是其操作可以将处理器的存储器总线和加载/存储单元旁路以便可以获得同硬件一样的处理速度。

图10:通过在可配置处理器中增加数据流直达处理模式来将执行部件和多个队列相结合
即使在处理器扩展中使用大量的硬件,但在定义时也只是仅仅写如下四行TIE代码而已:
queue InData1 256 in
queue InData2 256 in
queue OutData 256 out
operation QADD {} { in InData1, in InData2, in SumCTRl, out OutData} { assign OutData = SumCtrl ? (InData1 + InData2) : InData1; }
前三行代码定义了一个256位的输入队列和一个256位的输出队列,第四行定义了一条新的处理器指令QADD,该指令执行256位的加法运算或者将256位的数据从输入队列送到输出队列。通过TIE语言定义的指令告诉Xtensa处理器产生器自动为处理器增加相应的硬件,同时为处理器软件开发工具增添一条新指令。
用于多处理器片上系统 MPSOC 设计的处理器核
可配置处理器的出现使得片上系统SOC设计人员可以建立起一种崭新的且非常灵活的硬件模块构建方法。同传统的固定指令集体系结构ISA处理器相比,可配置处理器通过添加用户定制的执行功能部件、寄存器和寄存器堆以及专用通信接口能够获得很高的系统性能。
自从1971年第一个 微处理器 研制成功至今已经30多年,由于受固定处理器核的束缚,导致可配置处理器的发明无法实现。对于二十一世纪的片上系统SOC设计而言,这些制约因素已经不再存在,而且这些过时的约束也不再限制系统设计人员对处理器的使用。
本文关键字:微处理器 DSP/FPGA技术,单片机-工控设备 - DSP/FPGA技术






