多总线结构
例如TMS320C54X结构中有一组程序总线(PB PAB),两组读数据总线(CB CAB)、(DB DAB),和一组写数据总线(EB EAB),这样可以同时读取两组数据和存储一组数据,即同一时钟周期内可以执行一条3个操作的指令。这种附加总线和扩充地址增加数据流量,提高寻址能力。
采用流水线操作
计算机在执行一条指令时,要通过取指、译码、取数、执行等各阶段。由于DSP哈佛结构指令的各个阶段可以重叠进行,这样对每一条指令似乎都是在一个周期内完成,可以把指令周期减到最小,增加数据吞吐量。
这种流水线操作也不是十全十美的,其主要原因是,一项处理很难被分解成若干个处理规模一致、在时间上有最佳配合的流水段,因而需要用寄存器协调流水线工作。
流水线操作适用于循环操作时间足够长或多个数据点反复执行同一指令的情况。这是由于,流水线启动和停止的阶段是流水线逐步被填满和出空的过程。对于一次性非重复计算,流水线不可能达到稳态,反而用主要时间做填满和出空操作,因而是不合适的。
硬件乘法器和高效的MAC指令
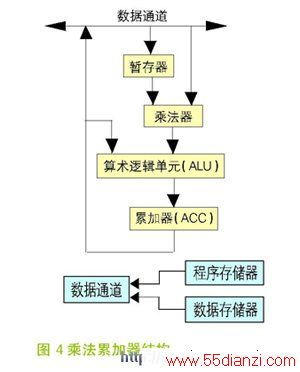
在DSP算法中,乘法累加操作是大量的运算。因而DSP芯片都有硬件乘法器,使得乘法运算做到一个周期内完成。与之配合的指令为MAC-乘法累加指令,其功能如图 4 所示,它可以在单周期内取两个操作数相乘,并将结果加载到累加器。有的DSP还具有多组MAC结构,可以并行处理。
独立的传输总线及其控制器
处理器高速处理速度必须与高速的数据访问和传输相配合。而且为不影响CPU及其相关总线的工作,DSP的DMA单独设置了传输总线及其控制器,因此DMA可以独立工作。
为了提高DSP的实时处理能力,有时把多个DSP组成DSP处理器阵列,并行工作,此时DMA成为各处理器之间进行数据传输的主要通道。
专用的数据地址发生器(DAG)
在DSP运算中,存储器的访问具有可预测性。例如在FIR滤波中,样本、系数都是顺序访问的,因此在DSP芯片中专门设置数据地址发生器。其实它也是一个ALU单元,具有简单的运算能力。在通用机的CPU中,数据地址和数据处理都由同一ALU完成。例如在8086中,做一次加法需要三个周期,而计算一次地址需要5~6 周期,这样会耗费大量的时间。在DSP芯片中就不需要这样的额外开销。另外在DSP芯片的数据地址产生中还支持间接寻址、循环寻址、倒位寻址等特殊操作,以适应DSP运算的各种寻址需求。
www.55dianzi.com
丰富的外设(Peripherals)
DSP 处理器 往往是脱机独立工作,因此为与外设接口方便,往往设置了丰富的周边接口电路。一般包含下列几种主要外设:
时钟产生器(振荡器与锁相环PLL);
定时器(Timer);
软件可编程等待状态发生器,以便使较快的片内设施与较慢的片外电路及存储器协调工作;
通用的I/O口;
多通道同步缓冲串口(McBSP)和异步串口;
主机接口(HIP)
JTAG边界扫描逻辑电路(IEEE 标准1149. 1),便于对DSP处理器做片上在线仿真和多处理器情况下的调试。
具有片内存储器
DSP芯片片内一般带有存放程序的只读存储器ROM和存放数据的随机存储器RAM,符合DSP运算简单、核心程序短小的特征,同时可以提高指令传输效率,减小总线接口压力。并且它不存在与外部总线竞争和访问外部存储器速度不匹配的问题,这样使DSP处理器具有强大的数据处理能力。
与结构相配合的采用RISC指令集
一般DSP处理器具有高度专门化、复杂且不规则的指令集,这样单个指令字可以同时控制片内多个功能单元操作。DSP处理器指令集在设计时有两个特点:其一是最大限度的使用了处理器的硬件资源,因此往往是在单个指令中并行完成若干操作。例如在完成主要算术运算的同时,并行地从存储器提取一个或两个数据以及完成地址指针的更新。其次是指令所使用的存储空间减到最小,为缩短指令字长,往往用状态寄存器的模式来控制处理器的操作特性,例如舍入或饱和的处理,而不再将这些信息作为指令的一部分来处理。
由于传统DSP芯片指令集的高度专门化及多功能操作使它难以用高级语言编译,所以一般C编译效率不高。另外C语言也不适合用来描述这种多存储空间、多组总线、高度专门化结构的硬件系统,这些都是导致用C编译传统DSP处理器效率不高的原因。
综上所述DSP处理器实现高速运算的主要途径可以概括为:具有硬件乘法器及乘-加单元;高效的存储器访问;零开销循环;专门的适应硬件结构的指令集;多执行单元;数据流的线性I/O口。
DSP处理器性能指标
对DSP处理器缺乏一种诸如对PC机那样公正合理的性能评价体系,这是由于各DSP厂商推出的产品在结构和数据传输能力上有很大的差异,它是专门为某种目的而设计的,因而正确评价只有与特定的应用联系起来,评价结果才有意义。这里将常用的指标评价方法做一介绍。
www.55dianzi.com
传统评价方法,这是最简单的评价指标:
MIPS(Millions of Instructions Per Second),一般 DSP 为20~100MIPS,使用超长指令字的TMS320B2XX为2400MIPS。
MOPS(Millions of Operations Per Second),每秒执行百万操作。这个指标的问题是什么是一次操作。通常操作包括CPU操作外,还包括地址计算、DMA访问数据传输、I/O操作等。一般说MOPS越高意味着乘积-累加和运算速度越快。
MFLOaPS(Million Floating Point Operations Per Second),这是衡量浮点DSP芯片的重要指标。例如TMS320C31在主频为40MHz时,处理能力为40MFLOPS,TMS320C6701在指令周期为6ns时,单精度运算可达1GFLOPS。
MBPS(Million Bit Per Second),它是对总线和I/O口数据吞吐率的度量,也就是某个总线或I/O的带宽。例如对TM
S320C6XXX、200MHZ时钟、32bit总线时,总线数据吞吐率则为800Mbyte/s或6400MBPS。
MACS(Multiply-ACCumulates Per Second),例如TMS320C6XXX乘加速度达300MMACS~600MMACS。
以上传统指标虽然可以作为设计时可选的参考指标,但是有很大的局限性。例如它没有考虑存储器的使用和器件的功耗,一旦器件与外部速度较慢的存储器进行数据交换时,运行速度马上就会被降低。
另一评价指标是核心算法评价指标。它是利用构成大多数DSP系统的基本运算模块,例如FIR、IIR、FFT、向量加等典型运算。规定大小适度、统一输入、输出要求,在保证功能一致性的条件下,也允许程序员针对所使用的处理进行代码的优化,评价指标是执行时间、存储器的使用和能耗等。
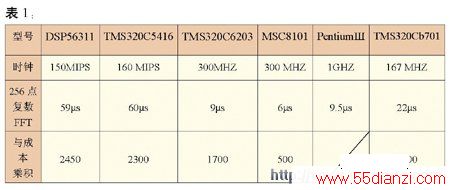
表1是对一些 处理器 评价的结果,其中DSP53611和MSC8101是MOTOROLA产品,TMS320C5416\6203是TI公司产品。TMS320C6701和Pentium Ⅲ属于浮点运算。
这种评价方法很容易用软件仿真或基于硬件应用的开发工具来决定执行的周期数。
从上列执行时间可以看出处理器结构对其性能的影响。例如TMS320C6203,时钟300MHZ,由于采用超长指令字结构、每个指令周期内处理8条指令,因此等效为2400MIPS,与TMS320C5416相比MIPS之比为15:1。但执行同样的256点复数FFT所需时间之比为7.8:1,因此两者用MIPS作为比较指标就有差距。其原因是C6203指令比C5416简单,因而完成同样任务需要更多的指令,另外也由于数据的独立和流水作业的影响等因素,C6203的并行性不能同时得到最佳的发挥。并且,这种核心算法评估指标并没有反映出计算精度,提高计算精度意味着字长的增加或采用浮点运算,相应的存储器容量增加,这些情况都没有能在指标中反映。
DSP处理器还有其他评估指标,各类评估指标之间都有其自身的不足,因而正确的选用器件要根据任务需要量身定做,不可一味追求某项高指标,要根据性能价格比合理选用器件。
本文关键字:处理器 DSP/FPGA技术,单片机-工控设备 - DSP/FPGA技术
上一篇:接触电容式感应接口设计






