1 引言
引入全球定位系统(GPS)的时钟信号作为时间基准,可以实现转子角的广域测量,从而可以直接监视发电机的动态行为,必要时实施控制,保证电力系统的安全稳定运行[1]。但是受到经济性、通信容量等因素的限制,不可能在每一台发电机处都装设转子角测量装置,需要进行优化配置。基于GPS的转子角测量装置与相量测量装置(PMU)在统一时标及功能上具有相似性,因此可以参考PMU的配置方法,主要有三种:① 在满足系统可观的条件下,实现PMU的最小配置[2];② 将系统划分成多个同调区域,原则上,每个区域只需配置一台PMU[3];③ 使PMU配置所得响应的信息含量最大,采用贪婪算法进行顺序配置[4]。第一种方法所需的PMU较多,是系统全部节点数的20%到30%左右;第二种方法所需的PMU数量较少,但同调区域划分难以考虑运行方式和扰动的变化;在第三种方法中配置地点的候选集合是事先指定的,没有依据,且贪婪算法不能保证求得最优解。
本文将同调分群与基于信息含量的方法相结合并且采用系统聚类分析,提出了一种转子角测量装置的优化配置方法。这种方法计及了多动态场景,通过系统聚类分析将场景集压缩。由同调分群形成配置地点的候选集合,引入电气距离指标,使不同机群的电气距离尽可能远。以Gramian行列式作为信息含量的表征,采用Tabu搜索算法从候选集合中有效地求得最优解或次优解。实际系统的仿真结果表明了这种配置方法的合理性和有效性。
2 问题定义
转子角测量装置的优化配置是一个有约束的最优化问题,旨在以最少数目的配置正确地反映系统的动态行为。对一个 nG机系统(NG 表示发电机集合),可表示为
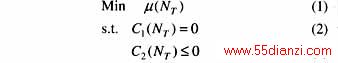
式中 NT⊆NG表示装设转子角测量装置的发电机;μ(NT)表示装置数目;C1和C2分别表示等式与不等式约束。
将发电机的转子角时间序列矩阵(简称为转子角矩阵)作为表征系统动态的基本数据,即

式中,每一列各表示一台发电机的转子角序列,m是扰动后时间窗内的采样数。
将信息含量作为衡量配置性能的指标,式(1)~(3)所定义的优化问题可进一步表示为
![]()
式中 R
(NG) 和R
(NT)分别表示发电机集合及其子集的转子角矩阵;I是信息含量的表征。
在用发电机集合的子集代表全集时,信息含量损失不可避免。因此,实践中,往往采用I (R
(NT))≈I (R
(NG))代替式(6),表示信息含量近似相等。
式(5)、(6)的另一种表述方式是给定转子角测量装置的数目,使发电机集合的某个子集的信息含量最大,即
![]()
注意到,式(5)、(6)和式(7)、(8)中没有给出不等式约束。如果需要,也可以加入表示经济及技术限制的不等式约束[4]。
3 配置方法
3.1 概述
电力系统的动态行为随着运行点以及扰动等的变化而变化。为了准确地反映系统的动态行为,进行大量的数字仿真实验以涵盖不同的动态场景。每仿真一个场景sÎS(S表示动态场景集)就得到一个由式(4)所定义的转子角矩阵R。将R作为基本数据,采用同调分群结合基于信息含量的方法可以求解由式(5)、(6)或式(7)、(8)所定义的最优化问题,但工作量大,实现起来困难。需要对原始的场景集进行压缩。概括起来,本文所提出的转子角测量装置的优化配置方法由以下三步构成:
(1)挖掘不同动态场景之间的相似性,将原始的动态场景集压缩至易于处理的规模;
(2)对压缩场景集中的每一个场景进行同调分群,以一台发电机代表一个同调机群,组成配置地点的候选集合;
(3)以Gramian行列式作为信息含量的表征,从候选集合中选出对应于每一个场景的配置地点,将对应于不同场景的配置结果组合起来得到最终的配置地点。
3.2 动态场景聚类
无监督学习技术包括统计相关分析、系统聚类和Kohonen特征映射等,适于挖掘数据之间的相似性。本文采用系统聚类中的类平均法对动态场景集进行聚类、压缩。
假设有n个数据,系统聚类的算法描述如下[5]:
(1)将n个数据分为n类;
(2)将相似性最大或不相似性最小的两类合并成一类,以这个新类代替原来的两个旧类;
(3)计算新类与其他各类之间的相似性或不相似性;
(4)重复步骤(2)和(3)直到所有的数据都合并为一类。
类平均法是整体性能最好的系统聚类方法之一[6],其中聚类CK和CL
之间的不相似性定义为

式中 xi和xj分别表示CK与CL的第i个和第j个数据;NK
和NL分别是CK与CL的数据个数;d (xi, xj)表示数据xi和xj之间的不相似性或距离。
将相关系数作为数据xi和xj之间相似性的度量,数据之间的距离表示为
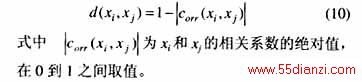
设总共仿真了nS 个动态场景,将它们所对应的nS个转子角矩阵按如下的形式重排为

聚类分析的数据基。
通过设置距离阈值dis,将原始的动态场景集分成多个类。dis值越小,类就越多,反之亦然。如何确定dis值并没有统一的准则。根据式(10)的定义,在0.15到0.2之间设定dis值是合理的,因为在该阈值下每一类的各个场景是强相关的(相关系数的绝对值在0.8到0.85之间)。每一类取一个场景作为代表,组成压缩场景集S
本文关键字:测量 电工技术,电工技术 - 电工技术






