1. 引言:
NIOSII 系列软核处理器是ALTEra公司的第二代FPGA(可编程门阵列)嵌入式处理器,主要利用了 SOPC (System on a programmable Chip)技术,通过将包括32位高性能处理器在内的多种应用模块嵌入到一个通用的FPGA/CPLD(复杂的可编程逻辑控制器件)内,实现一个完全可重置的嵌入式系统。
嵌入式系统SOC,可基于现场FPGA/CPLD或专用集成电路(ASIC).SOPC片上可编程系统是Altera公司提出来的一种灵活、高效的解决方案,它将处理器、存储器、I/O端口、网络接口等系统设计需要的东西集成到一个PLD(可编程逻辑器件)器件上,构建成一个可编程的片上系统,具有灵活的设计方式,可裁减、可扩充、可升级,具备软硬件在系统可编程的功能.SOPC技术中以Nios为代表的RISC(精简指令集)处理器IP核以及用户以HDL语言开发的逻辑部件,可以最终综合到一片FPGA 芯片中,实现真正的可编程片上系统。
在嵌入式SOPC系统中,由于处理器设计、器件性能、系统外设等原因,整体性能比较差,提高嵌入式系统性能,成为嵌入式系统发展的 一个趋势。为此,Altera提供了多处理器支持,但在 SMP (对称多处理器)构架下,并没有解决缓冲区一致性问题,本文对此提出了解决方案,并对上层软件设计的关键问题提出了解决方法。
2. NiosII与 Avalon总线
NiosII是一种32位、哈佛结构、5级流水线的RISC处理器,它有32个32位通用寄存器和5个32位控制寄存器,支持缓存、中断、自定义指令,外部数据和地址总接口使用简单的Avalon总线,指令支持算术运算,关系运算,逻辑运算,移位运算,系统内集成UART、PIO、SPI、时间控制器、网卡等IP核,性能可超过150 MIPS。系统具有可编程性、可扩展性等灵活特点[3]。
Avalon总线是一种相对简单的总线结构,用于连接处理器与外设,以构成可编程单芯片上系统。它描述了主从构件间的端口连接关系,以及构件间通信的时序关系。Avalon总线在主设备和从设备之间能够实现字节、字、长字数据传输,总线也支持高级特征,如延迟设备、流设备、多主设备,这些高级特征保证多个数据单元在单一总线交易期间在外围设备间传输。Avalon主设备和从设备之间相互作用,且没有技术上的关联性,称之为从侧仲裁。如果多个主设备试图同时访问同一个主设备,从侧仲裁决定哪一个主设备获得访问从设备。如图:
3. 硬件架构设计
目前,大多数 SMP系统的处理器通过高速监听总线(snoopy bus)连接处理器和共享存储器,由于争用共享总线和争用共享存储器,从而限制了总线型的 SMP 系统中处理器的数目。为了解决此问题,现在的 SMP 系统基本上都采用增大高速缓存容量的方法来减少抢占内存,因为高速缓存是处理器的“本地内存”,它与处理器之间的数据交换速度远远高于内存总线速度,又由于高速缓存不支持共享,这样就不会出现多个处理器抢占同一段内存资源的问题了,许多数据操作就可以在处理器内置的高速缓存或外置的高速缓存中顺利完成。然而,高速缓存的作用虽然解决了SMP系统中的抢占内存问题,但又引起了另一个较难解决的缓冲区一致性问题。其解决方法分为两类:目录协议、监听协议。
从上节对Avalon总线介绍可知,Avalon总线是由系统自动生成的,内部集成了仲裁器,用户无法监控总线上的信号,那么传统的目录协议、监听总线协议将不适用于此系统。为此,必须对其改进。文献1提出解决方案,其设计思想:监听从设备端的读写信号,当发生写时,锁存地址,并中断所有CPU,CPU根据ISR确定缓冲区中的无效行。
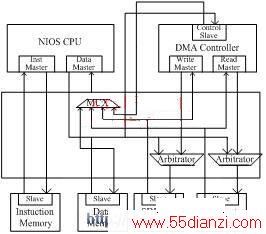
在CCM(cache coherency module)模块设计时,根据具体需要来设计。方案1是根据监听片外资源数来确定监听FIFO的数量、多CPU共享同一中断源[1]。方案2是根据CPU的数量来设置监听FIFO的数量、独占中断源。在这里采用了方案2,其主要是基于以下几点:所有的CPU享有独立的中断源、提供多CPU交互功能、提供了各个CPU的并行性。在方案1中,使得任一CPU都要进行同一ISR的处理,则最佳情况下为24条指令周期(这里指进入ISR程序以后),最坏情况下需要8+16N条指令,N代表监听总线上发生的次数。方案2在双核的情况下与方案1的资源占用相同,且在设计、调试等方面都比较快捷、方便。下面给出其结构框图:

CCM模块主要解决缓冲区一致性问题,并且提供多CPU之间中断功能。MUTEX为NIOS提供的组件,它提供一种基于硬件的原子测试-设置(test-and-set)操作,其主要功能是解决多个CPU争用共享设备。RAM1、RAM2分别为CPU1、CPU2所独占,SRAM及其它外设为共享设备。
www.55dianzi.com
方案2中CCM总体结构主要两部分组成:Avalon总线接口模块、写监听模块。Avalon总线接口模块为每个CPU提供一个访问控制CCM的接口,同时产生不同的中断源IRQ信号(本方案中为两个接口)。写监听模块主要是监听SRAM上写信号,将写地址锁存在FIFO中,其中FIFO调用了同步的LPM_FIFO。且各个CPU占用独立的FIFO,则各个CPU之间可以独立的工作,不需要相互等待,有效地减小了访问时间。
4. 软件关键问题设计
4.1 CPU的识别
SMP 系统中,多个CPU共享数据据区,那么如何识别CPU,在NIOS系统中,有如下方法:改变CPU ID寄存器,加入控制寄存器,运用小容量的ROM来存贮不同的ID号,运用自定义指令[1]。在这里,使用了自定义指令,其主要原因是:需要的资源很少(一个32位寄存器),相同的指令在不同的CPU可以执行不同的功能。
在 SOPC Builer 中运用 NIOSII 自定义Combinatorial指令类型分别导入CPU1、CPU2中,SOPC Builer自动生成PTF文件,并在IDE中映射生 成system.h文件,生成自定义宏函数ALT_CI_CPUID(A)。
SMP 系统中的处理器分为 BSP 和 AP。在系统启动时,BSP 负责初始化硬件和启动操作系统,然后唤醒 AP 一起工作。在这里CPU1为BSP,CPU2为AP。 ALT_CI_CPUID函数在CPU1执行时返回0,CPU2执行时返回1,从而完成了程序的分流执行。
4.2 ISR
ISR是中断服务程序,在这里主要完成来自CCM的中断处理,其处理流程步骤如下:关中断(可选),读取CCM寄存器,判断其中断类型(是多CPU之间中断还是缓冲区中断),然后分别执行,清除中断源,开中断(可选)。
4.3 资源互斥
多处理器中的互斥技术是在单处理器互斥技术的基础之上发展起来的。与单处理器系统相比,多处理器系统中的互斥问题更加复杂。在单处理器系统中,竞争条件主要发生当前进程被中断的时候和当前进程被抢占的时候,其解决方法主要有:关中断、信号量、禁止任务切换、使用测试并置位等方法。而在多处理器系统中,即使在当前进程没有被中断也没有被抢占的情况仍然需要互斥(即不同处理器上的进程访问了相同的数据),那么通过关中断、禁止任务切换的方法将不能实现互斥,其解决方法是在测试并置位的基础上实现信号量、自旋锁。示例程序如下:
struct semaphore
{ int count;
int sleepers;
wait_queue_head_t wait;
};
struct semaphore sem;
Void task1()
{
alt_mutex_dev* mutex = aLTEra_avalon_mutex_open( “/dev/mutex” );
altera_avalon_mutex_LOCk( mutex, 1 );
Sem.count= Sem.count-1;
altera_avalon_mutex_unlock( mutex );
Sem.count= Sem.count+1;
}
程序首先定义了信号量,其中count表示临界资源的数量,altera_avalon_mutex_lock()、altera_avalon_mutex_unlock()为Mutex加锁、解锁函数。信号量可以解决单处理器下的程序同步问题,但当在多处理器下时,可能会有多个CPU同时访问信号量,且信号量为可用,那么多个CPU都会使用临界资源,使程序发生异常,所以在使用信号量前加入测试并置位指令就可以实现了多处理器的互斥。
系统Mutex IP核它的争用是采用固定选择策略,即如果CPU1与CPU2同时争用,则它们中的一个总是先占用,在某种特殊需求时可能无法满足用户需求。用户可以通过自定义指令,外挂用户自定义判定逻辑来产生互斥功能部件。
5创新点总结
本文介绍的基于NIOSII多处理器硬件架构及上层软件的设计,这里并没有涉及到操作系统的移植,其主要是根据系统的需求而定。分析整个系统可以知道,系统可以并行执行用户的几个程序,提高系统的吞吐量,可以控制相对比较多的I/O设备,且因为Avalon总线的“点对点”特性,使得并行性得以提高,同时也可以基于安全的考虑,作为CPU的冗余。
提出了基于异步的监听FIFO的解决方案,在双核条件下资源占用与方案1相同,但其性能有显著提高。在方案1中调用了两片LPM_FIFO,其单个FIFO资源使用为35个LC、672个MB。在方案1中,ISR要访问三次CCM、而在方案2中仅需要一次、且不需要等待其它CPU访问CCM。
本文关键字:处理器 综合-其它,单片机-工控设备 - 综合-其它
上一篇:TD-SCDMA手机校准应用方案






