摘要:本应用笔记说明了如何计算DS31256 HDLC控制器的总线带宽。并展示了一个实验室实测的结果。同时演示了一个总线利用率速算表,该速算表如果需要可以索要。
概述
DS31256 HDLC控制器通过PCI总线存取发送和收到的HDLC包。本应用笔记讨论如何计算DS31256正常工作所需的总线带宽。所涉及到的相关术语的定义在本文的开始部分给出。
根据本应用笔记所提供的信息,用户只需适当调整速算表(备索)中的一些数据,就可将它用于特定的应用中。
表1. 本应用笔记所涉及到的变量的定义 VariableDefinitionValid RangeBAverage number of packets processed before the host updates the receive free queue and transmit pending queue or reads the receive done queue and transmit done queue1, 2, 3, . . . .CAverage number of bus cycles required per packet1, 2, 3, . . . .DNumber of bus cycles needed for data to be transferred1, 2, 3, . . . .PPacket size in bytes64RAverage number of bus cycles added due to latency in RAM access0, 1, 2, . . . .XAverage number of bus accesses required to send or obtain packet data to, or from the data buffers1, 2, 3, . . . .
总线访问类型
DS31256或主机执行四种类型的总线访问,以支持DS31256内的直接存储器访问(DMA)。在下面的讨论中,变量D定义为数据周期数,变量R定义为由于RAM访问时间的关系,所需要的总线周期数。
访问类型1:DMA突发读主机RAM
当DMA突发读主机RAM时所需要的总线周期总数为[3+R+D]。这可由图1和表2得出。
表2. DMA读所需的总线周期总数 CycleNo. Cycles RequiredAddress Cycle1Turnaround Cycle1RAM Access Latency CycleRData CycleDTurnaround Cycle1

图1. DS31256 PCI总线读
访问类型2:DMA突发写主机RAM
当DMA突发写主机RAM时所需的总线周期总数为[2+R+D]。这可从图2和表3得到。
表3. DMA写所需的总线周期总数 CycleNo. Cycles RequiredAddress Cycle1RAM Access Latency CycleRData CycleDTurnaround Cycle1

图2. DS31256 PCI总线写周期
访问类型3:主机写DS31256
主机写入DS31256时所需的总线周期总数为7。
访问类型4:主机读DS31256
主机读取DS31256时所需的总线周期总数为7。
注意:对于访问类型3和4,7个访问周期是DS31256所固有的,不能改变。
每个包所需的总线周期数
为计算总线利用率,首先必须知道所需要的总线周期数。为得到该数据,我们做了一些假设列于表4。图3给出了在收到或发出一个数据包时主机和DMA将要执行的标准流程。根据图3,我们有可能得出一个公式,来计算每个包所需要的平均总线周期数,即变量C。
发送侧
发送侧周期 = 读等待队列 + 写水平描述符链 + 读描述符 + 从主机存储器读取包 + 写完成队列 + 读/写寄存器。
Ct = [(3 + R + 12)/12] + [2 + R + 1] + [3 + R + 4] + [(P/4) + (3 + R)X] + [(2 + R + 6)/6] + [4(7/B)]
接收侧
接收侧周期 = 读自由队列 + 将包写入主机存储器 + 写描述符 + 写完成队列 + 读/写寄存器。
Cr = [(3 + R + 24)/12] + [(P/4) + (2 + R)X] + [2 + R + 3] + [(2 + R + 6)/6] + [4(7/B)]
总公式
Ct + Cr = 21.16 + 3.5R + 0.5P + (5 + 2R)X + 56/B
表4. 为了便于计算每个包所需总线周期数所作的假设 1All packets are 64 bytes (seen as worst case).2The Frame Check Sequence (FCS) of the HDLC packet is not transferred to, or from the PCI bus.3On the receive side, only large buffers are used (small buffers are disabled).4The receive DMA will burst read the free queue and burst write the done queue.5The transmit DMA will burst read the pending queue and burst write the done queue.6All packets fit within a single buffer (i.e., only one deSCRJPTor). This is reasonable because packets are 64 bytes.7All physical layer links are filled with packets; no idle codes are sent or received.8Interrupt routines and overhead (like accesses to the local bus) are not considered.

图3. 每个包的总线处理流程
注:
- 12个描述符 x 1双字 = 12个发送等待队列描述符双字
- 包数据字节数 = 4字节/数据周期
- 6个描述符 x 1双字 = 6个发送完成队列描述符双字

图3. (续)
注:
- 12个描述符 x 2双字 = 24个接收自由队列描述符双字
- 包数据字节数 = 4字节/数据周期
- 6个描述符 x 1双字 = 6个接收完成队列描述符双字
PCI总线利用率
总线利用率定义为DS31256每秒所需的总线周期数除以每秒可供使用的总线周期总数。总线利用率可按照特定的HDLC配置和业务量计算。计算中假定PCI总线时钟速率为33MHz (33,000,000Hz),并且只用一片DS31256。以下就是PCI总线利用率的详细计算方法。
公式1:

公式2:
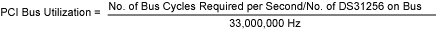
注:
举例
有关PCI总线利用率的实验室测量结果展示了DS31256的PCI总线使用情况。其中假定所有收到的和发出的数据包都为56字节长(P = 56)。结果归纳于表5。我们还制作了一个可以计算总线利用率的速算表(如表6所示),如果需要可以索要(请联络 <SCRJPT language=javaSCRJPT> var name = "telecom.support@"; var domain = "maxim-ic.com"; document.write ("
表5. PCI总线利用率实验室实测数据 BPR ModeNo. of PortsAvg. No. Done Queues Entries ProcessedPkt Size (Bytes)Avg. RAM Access Latency CyclesNo. of HDLC ChannelsTotal No. of ChannelsChannel Data Rate (kbps)PCI Clock Rate (MHz)PCI Bus Util.(%)High Speed314.17568.3513525247.55Unchannelized335.53568.5013292949.06Low Speed16100.465610.60116121255.27Unchannelized1624.305610.24116101052.54T1168.081567.137512192128 *1.54418.26E1168.154567.8645162561282.04828.072E11610.894568.003162562564.09655.824E116381.207568.3123812810248.19250.97
* 注:
- 每个T1帧有193位 = [(24时隙 x 8位) + 1个同步位]
- 每个时隙的数据速率为64,000位/秒
- (64,000位/秒)/8位 = 8,000帧/秒
- 每125微妙到达一个T1帧 = 1/(8,000帧)/秒
- 数据速率为1,536,000位/秒 = 24信道 x (8位/信道/帧) x (8,000帧/秒)
- 线路总速率为1,544,000位/秒 = [(24信道 x (8位/信道)) + (1同步(位/帧))] x (8,000帧/秒)
表6. DS31256 PCI总线利用率速算表 Input Variables B14.17The average number of packets processed before the host updates the Receive Free Queue and Transmit Pending Queue, or reads the Receive/Transmit Done Queues.P56The size of the packet in bytes.R8.35The average number of bus cycles added due to latency in RAM access.Number of HDLC channels per DS312563Use 1 per active port when operating in unchannelized mode.Channel Data Rate (kbps)52,000.00Note that T1 speed == 1536kbps.Channel Utilization Rate39.5%There can be time between packets in real applications.PCI Clock Rate (MHz)33 PCI Latency/Transaction10This is based on the average number of cycles required to perform each of the transactions associated with processing a packet. Our designers use 10 in their simulations, which is fairly conservative.Number of DS31256's on Bus1 Intermediate Variables C104.04The average number of bus cycles required per packet.X1.00The average number of bus accesses required to send/obtain packet data to/from the data buffers.Packets/second/channel45,871.43 Total PCI Latency1,376,142.86 No. of Bus cycles required/sec15,693,122 Half Duplex Full DuplexBus utilization47.6%95.11%Bus Capacity (Mbps)264 Bus Throughput (Mbps)125.54251.09
注:

其中,1024 blocks是FIFO的尺寸,FIFO的高、低水印被设置于50%。
结束语
本应用笔记解释了如何计算在给定应用中,DS31256对于总线带宽的要求。提供了一些实验室测试的实例。并提供了一个可执行这种计算的电子速算表,如果需要可以索取。
本文关键字:暂无联系方式电力配电知识,电工技术 - 电力配电知识






